Xin chào các bạn!
Trong bài post này, mình sẽ giải ngố về giải thuật non-maximum suppression (NMS) thường được dùng trong khâu post-processing của YOLO models.
1. NMS giải quyết vấn đề gì ?
Nếu các bạn đã từng dùng các thư viện Ultralytics để chạy các mô hình YoloV8, Yolov5 hoặc các repo Yolo trên github, thì output YOLO xuất ra cho chúng ta thường nằm ở định dạng x_center, y_center, width, height, class, confidence_score. Tuy nhiên, đó là những output đã được hậu xử lý, và khi các bạn chuyển qua các định dạng khác như ONNX, tflite, TensorRT, OpenVINO, … để deploy trên các ngôn ngữ khác như Java, Javascript, C++ thì các output của model sẽ nằm ở dạng 8400 x Num_class + 4. Lý do của việc này là vì sau khi convert model qua ngôn ngữ khác thì khâu hậu xử lý mà tác giả viết (thường bằng Python) sẽ không được đính kèm theo và điều này buộc chúng ta phải viết lại khâu này bằng các ngôn ngữ chúng ta deploy. Giả sử chúng ta muốn deploy model detection lên web thì phải viết lại khâu hậu xử lý bằng ngôn ngữ Javascript, hoặc trên thiết bị nhúng bằng C++. Và điều này đòi hỏi bạn phải hiểu được thuật toán NMS để có thể viết lại.
2. Intersection over Union (IoU)
Để có thể dễ dàng hiểu và implement được NMS thì chúng ta cần phải hiểu được cách xấc định IoU của 2 bounding boxes. May mắn là IoU cực kì đơn giản.
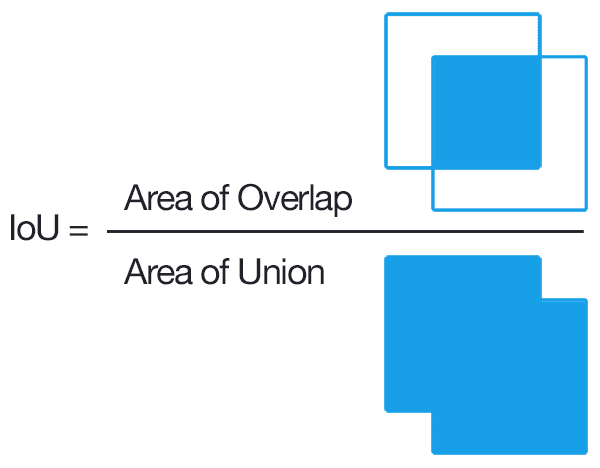
IoU sẽ được tính bằng cách lấy diện tích của phần giao chia cho diện tích của phần hợp.
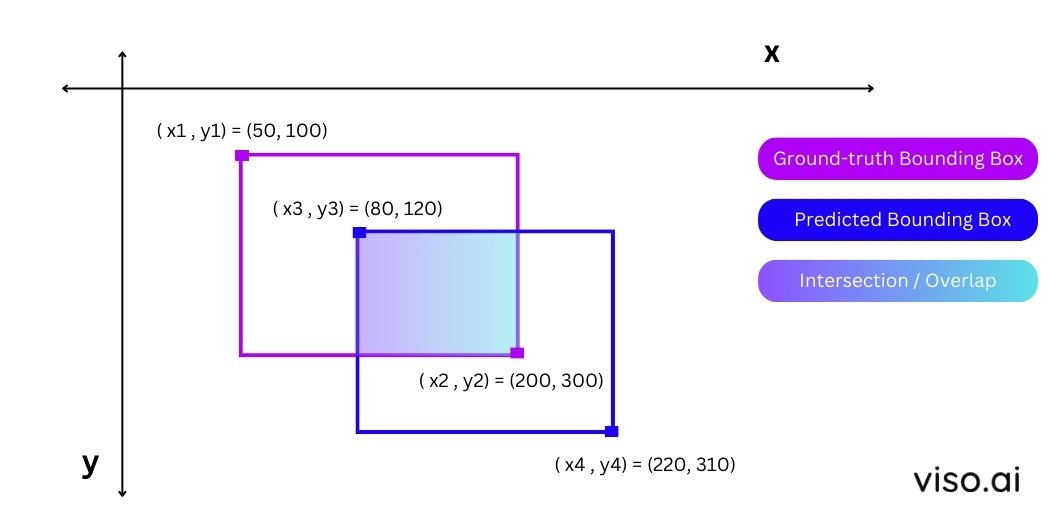
Như ở hình trên, giao của 2 bounding box là một bounding box có góc trái (x3, y3) và góc phải là (x2, y2) và diện tích của nó là H x W = (200-80)x(300-120) = 21600. Diện tích phần hợp bằng diện tích của 2 hình trừ đi diện tích của hình giao, vì vậy sẽ được tính như sau (200-50) x (300 - 100) + (220 - 80) x (310 - 120) - 21600 = 30000 + 26600 - 21600 = 35000. Lấy diện tích phần giao chia cho diện tích phần hợp, ta sẽ được ~0.6171 là IoU của 2 bounding boxes trên.
3. Thuật toán NMS hoạt động như thế nào ?
Như mình đã đề cập ở mục 1, output của mô hình YOLO có định dạng 8400 x Num_class + 4 và NMS sẽ giúp chúng ta chuyển từ định dạng này về định dạng chúng ta thường thấy là x_center, y_center, width, height.
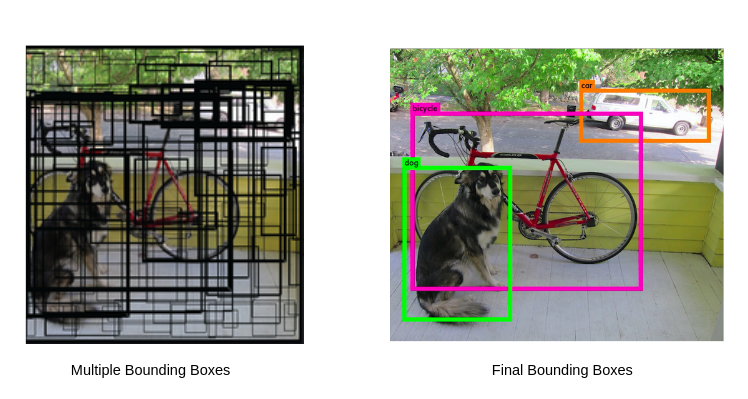 NMS lọc ra những bounding boxes tốt nhất từ một rừng những detections
NMS lọc ra những bounding boxes tốt nhất từ một rừng những detections
8400 là con số lượng detection boxes ở hình bên trái với chi chít ô vuông, Num_class + 4 là một vector chứa các giá trị classification score của mỗi class và 4 giá trị x_center, y_center, x_center, y_center. Vì vậy, nếu bạn huấn luyện để detect 2 class thì vector này sẽ có 6 giá trị. Ví dụ, nếu vector có dạng [0.009, 0.073, 0.2, 0.2, 0.3, 0.3] thì tức là classification score của class 1 là 0.009, class 2 là 0.073 và x_center nằm ở vị trí 0.2 độ rộng của bức ảnh, y_center nằm ở vị trí 0.2 độ dài của bức ảnh, và width và height của bounding box lần lượt là 0.3, 0.3. Vì vậy, thuật toán NMS sẽ giúp ta tìm ra những bounding boxes tốt nhất cho chúng ta như các bạn thấy ở hình bên phải.
Note: Nếu các bạn thắc mắc tại sao classification scores của các class không có tổng bằng 1 thì lý do là mô hình YOLO dùng Sigmoid activation cho mỗi class, vì vậy tổng của chúng sẽ có thể không bằng 1 như Softmax.
Khâu hậu xử lý trong YOLO gồm 5 bước,
Step 1: Lọc những detections có confidence score thấp
Trong settings của YOlO có một parameter là conf_thresh, tức là max confidence score để nó được chuyển qua step 2 để xử lý. Giả sử, nếu bạn set conf_thresh = 0.5 thì các detection với max confidence giữa các class là 0.45 thì detection này sẽ bị loại và ngược lại. Để minh họa, giả sử chúng ta có 3 class: người, chó, mèo và detection vector ở dạng sau [0.16, 0.08, 0.32, 0.2, 0.2, 0.3, 0.3] thì tức detection vector này sẽ bị loại vì max confidence score chỉ có 0.32.
Step 2: Ở bước này, ta sẽ dùng hàm argmax để tìm ra class có confidence score cao nhất của một detection. Ví dụ minh họa, nếu ta có detection [0.92, 0.8, 0.5, 0.2, 0.2, 0.3, 0.3] thì class đầu tiên sẽ được chọn. Và vector này sẽ được chuyển thành [0.2, 0.2, 0.3, 0.3, 1, 0.92], với 4 số đầu là vị trí, số gần cuối là class_id, và số cuối cùng là confidence score.
Note: Mình để step 2 để các bạn dễ hình dung chứ chính xác thì nó được chạy cùng với step 1 luôn để tiết kiệm chi phí tính toán.
Step 3: Ở bước 3, ta sẽ dùng một hàm để lọc ra các class như những bounding boxes thuộc class 1, những bounding boxes thuộc class 2, …
Step 4: Ở bước này, ở mỗi class ta sẽ loop qua các detection và tính IoU của 2 bounding boxes và nếu IoU lớn hơn một khoảng định trước (trong setting của YOLO là iou_thresh) thì 2 bounding boxes đó được xem là trùng và chúng ta chỉ lấy 1 bounding box mà có confidence score cao nhất trong số đó ra thôi. Nếu không trùng thì ta sẽ lấy cả 2.
Step 5: Tập hợp lại những detections ở các class và đó là output mà các bạn thường thấy khi dùng Ultralytics.
4. Coding time
Khi chuyển qua các format khác thì chúng ta sẽ bị mất khâu hậu xử lý, vì vậy mình sẽ hướng dẫn các bạn biến phần output thô này thành thông tin chúng ta mong muốn. Mình sẽ demo ví dụ dưới đây với format ONNX, format ONNX là format phổ biến nhất có thể deploy trên rất nhiều ngôn ngữ và platform. Và ở đây, mình sẽ perform class-aware NMS, class-agnostic NMS cũng tương tự tuy nhiên dễ hơn nha.
Đầu tiên, chúng ta hãy import những thư viện cần thiết và model,
import numpy as np
import matplotlib.pyplot as plt
import cv2
from ultralytics import YOLO
import onnxruntime as ort
model = ort.InferenceSession("./yolov8n.onnx", providers = ["CPUExecutionProvider"])
inputs = model.get_inputs()
input = inputs[0]
print(f"Input Name: ", input.name)
print(f"Input Type: ", input.type)
print(f"Input Shape: ", input.shape)
outputs = model.get_outputs()
output = outputs[0]
print(f"Output Name:",output.name)
print(f"Output Type:",output.type)
print(f"Output Shape:",output.shape)
> Input Name: images
> Input Type: tensor(float)
> Input Shape: [1, 3, 640, 640]
> Output Name: output0
> Output Type: tensor(float)
> Output Shape: [1, 84, 8400]
Chạy inference để xem output của model có gì nào, mình sẽ lấy tấm hình này để
demo

image = cv2.imread("./demo.jpg")
print(f"Raw image shape: {image.shape}")
rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
transformed_image = (cv2.resize(rgb_image, (640, 640)).astype("float32")/255.).transpose(2, 0, 1)[None, ...]
print(f"Transformed image shape: {transformed_image.shape}")
> Raw image shape: (415, 612, 3)
> Transformed image shape: (1, 3, 640, 640)
pred = model.run(["output0"], {"images": transformed_image})[0]
print(f"Shape of prediction: {pred.shape}")
> Shape of prediction: (1, 84, 8400)
pred = pred.transpose(0, 2, 1)[0]
Đây là function sẽ thực hiện bước 1 và bước 2
def parse_pred(pred, img_width, img_height):
# Trích xuất max confidence score của mỗi box
max_confidence_score_each_box = np.max(pred[:, 4:], axis = 1)
# Trích xuất ra indexes có max confidence score > 0.5, cái này các bạn có
# thể set tùy ý, mình recommend > 0.4
chosen_box_inds = np.where(max_confidence_score_each_box > 0.5)[0]
# Chọn ra những detections có max confidence score > 0.5
chosen_detections = pred[chosen_box_inds]
# Trích ra index của các class trong các detections được lọc
detection_classes = chosen_detections[:, 4:].argmax(axis = 1)
# Trích ra những confidence score cao nhất của box đó
detection_highest_confidence_scores = chosen_detections[:, 4:].max(axis = 1)
# Rescale về tọa độ của ảnh gốc
x1 = ((chosen_detections[:, 0] - chosen_detections[:, 2]/2)/640)*img_width
y1 = ((chosen_detections[:, 1] - chosen_detections[:, 3]/2)/640)*img_height
x2 = ((chosen_detections[:, 0] + chosen_detections[:, 2]/2)/640)*img_width
y2 = ((chosen_detections[:, 1] + chosen_detections[:, 3]/2)/640)*img_height
return np.hstack([x1[..., None], y1[..., None],
x2[..., None], y2[..., None],
detection_classes[..., None],
detection_highest_confidence_scores[..., None]])
Đây là function sẽ thực hiện giải thuật non-maximum suppression cho 1 class
def nms_for_one_class(boxes, scores, iou_threshold):
# Trích xuất vị trí các tọa độ
x1 = boxes[:, 0]
y1 = boxes[:, 1]
x2 = boxes[:, 2]
y2 = boxes[:, 3]
# Tính diện tích các area của các detections
areas = (x2 - x1 + 1)*(y2 - y1 + 1)
# Sort những indexxes có confidence score cao
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
width = np.maximum(0.0, xx2 - xx1 + 1)
height = np.maximum(0.0, yy2 - yy1 + 1)
intersection = width*height
iou = intersection / (areas[i] + areas[order[1:]] - intersection)
# Nếu IoU nhỏ hơn iou_threshold thì sẽ lưu vào
inds = np.where(iou <= iou_threshold)[0]
order = order[inds + 1]
return np.array(keep, dtype=np.int32)
Đây là giải thuật thực hiện khâu cuối cùng của hậu xử lý. Hàm này có tác dụng lọc ra những detection của từng class và chạy nms trên những detection của class đó. Và sau khi chạy trên tất cả các class, ta sẽ thu về được kết quả sau:
def last_step(parsed_pred):
unique_classes = np.unique(parsed_pred[:, -2])
finest_idxes = np.array([]).astype(int)
for unique_class in unique_classes:
uc_idxes = np.where(parsed_pred[:, -2] == unique_class)[0]
uc_detections = parsed_pred[uc_idxes]
boxes = uc_detections[:, :4]
scores = uc_detections[:, -1]
after_nms = nms_for_one_class(boxes, scores, iou_threshold = 0.7)
finest_idxes = np.append(finest_idxes, values = after_nms)
return parsed_pred[finest_idxes]
Đây là functions hoàn chỉnh,
parsed_pred = parse_pred(pred, image.shape[1], image.shape[0])
final_pred = last_step(parsed_pred)
print(f"Prediction after post-processing: {final_pred}")
> array([[ 140.52, 169.65, 255.55, 316.71, 17, 0.61475],
[ 262.22, 94.908, 460.41, 315.78, 16, 0.78507]])
Trong COCO class, class 16 là dog và 17 là cat, vì vậy trong tấm ảnh model detect được 2 vật thể là chó và mèo. Giờ chúng ta visualise kết quả sau khi vẽ prediction nhé.

Và thế là, sau một vài steps, ta đã thực hiện xong khâu hậu xử lý của YOLO!!
P/s: Nếu các bạn thắc mắc tại sao hai tấm ảnh cùng kích thước nhưng một tấm lại xử lý lâu hơn và tấm kia xử lý nhanh hơn thì đó chủ yếu là do khối hậu xử lý của YOLO nha. Vì có tấm ở step 1 và 2 đã lọc ra còn khoảng 3-4 detections nhưng có tấm sau step 1 và 2 vãn còn 400-500 detections.
Tài liệu tham khảo
- Ultralytics YOLO
- How to create YOLOv8-based object detection web service using Python, Julia, Node.js, JavaScript, Go and Rust