1. Giới thiệu về reinforcement learning
Reinforcement learning là một nhánh đặc biệt của học máy và không thuộc cả 2 loại supervised learning và unsupervised learning. Lý do nó không phải là supervised learning và unsupervised learning là vì phương pháp này không cần đến labels và không được thiết kế để tìm ra cấu trúc ẩn (hidden structure) của dữ liệu. Đây là một giải thuật học bằng trials-and-errors. Trong RL, chúng ta sẽ huấn luyện agent học cách hành động trong một môi trường (environment), ta chỉ cần đặt mục tiêu và agent sẽ tìm ra phương án để đạt được mục tiêu đó.
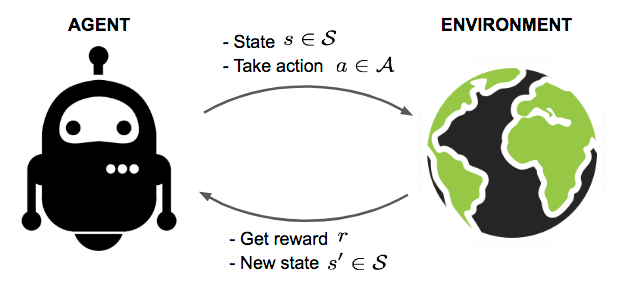
Ví dụ, trong cờ tướng chúng ta biết thế nào là thắng nhưng còn làm sao để thắng thì vẫn là ẩn số (LoL). Tương tự với Cờ vua, quay rubic, chứng khoán, Liên Minh Huyền Thoại, Fifa, đột kích, …, chúng ta đều biết như thế nào là thắng hoặc hoàn thành nhiệm vụ, tuy nhiên con đường đến đó chúng ta chưa biết. Và giải thuật reinforcement learning sẽ giúp tìm ra lời giải cho bài toán làm sao này.
2. Lịch sử của reinforcement learning
Reinforcement Learning (RL) bắt nguồn từ lý thuyết hành vi trong tâm lý học, với khái niệm thử và sai và phần thưởng từ thập niên 1950. Những nhà tiên phong như Richard Bellman đã phát triển các khái niệm nền tảng như Dynamic Programming và Bellman Equation, đặt nền móng cho lý thuyết RL. Trong những năm 1980, Watkins giới thiệu Q-learning, một phương pháp nổi tiếng giúp tác nhân học cách tối ưu hóa hành động mà không cần biết trước mô hình môi trường.
Tuy nhiên, RL chỉ thực sự bùng nổ vào đầu thập niên 2010, khi DeepMind phát triển Deep Q Networks (DQN), kết hợp RL với mạng CNN, cho phép agent học qua hình ảnh và đánh bại con người trong trò chơi Atari. Sau đó, thành công của các hệ thống như AlphaGo, OpenAI Five, ChatGPT, và nhiều ứng dụng trong tự động hóa đã đưa RL lên tầm cao mới, trở thành lĩnh vực nổi bật trong AI.
 Hình 1.2. AlphaGo đánh bại kỳ thủ cờ vây số 1 thế giới Lee Sedol
Hình 1.2. AlphaGo đánh bại kỳ thủ cờ vây số 1 thế giới Lee Sedol
3. Khái niệm và thuật ngữ trong RL
Trong phần này, mình sẽ giải thích các thuật ngữ được dùng thông dụng nhất trong RL như states, actions, policies, …
3.1. States and observations
Một trạng thái (state) \(s\) là mô tả hoàn chỉnh về trạng thái của agent trong môi trường. Một quan sát (observation) \(o\) là mô tả một phần của trạng thái, có thể bỏ qua một số thông tin. Tuy nhiên, trong nhiều tài liệu, họ vẫn sử dụng state và observation một cách đồng nghĩa.
Trong deep RL, chúng ta hầu như luôn biểu diễn các trạng thái và quan sát bằng một vector giá trị thực, ma trận hoặc tensor bậc cao hơn. Ví dụ, một quan sát hình ảnh có thể được biểu diễn bằng ma trận RGB của các giá trị pixel; trạng thái của một robot có thể được biểu diễn bởi các góc khớp và vận tốc của nó.
Khi agent có thể quan sát toàn bộ trạng thái của môi trường, chúng ta nói rằng môi trường được quan sát đầy đủ (fully observed). Khi agent chỉ có thể thấy một phần quan sát, chúng ta nói rằng môi trường được quan sát một phần (partially observed).
3.2. Action spaces
Các môi trường khác nhau cho phép các loại hành động khác nhau. Tập hợp tất cả các hành động hợp lệ trong một môi trường nhất định thường được gọi là action space. Một số môi trường, như Atari và Go, có không gian hành động rời rạc (discrete action space), nơi chỉ có một số lượng hữu hạn các nước đi có sẵn cho agent. Các môi trường khác, như khi tác nhân điều khiển robot trong thế giới vật lý, có không gian hành động liên tục (continuous action space). Trong các không gian liên tục, các hành động là các vector giá trị thực.
Sự phân biệt này có những hệ quả khá sâu sắc đối với các phương pháp trong deep RL. Một số họ thuật toán chỉ có thể được áp dụng trực tiếp trong một trường hợp, và sẽ phải được sửa đổi đáng kể để áp dụng cho trường hợp khác.
3.3. Policies
Policy là quy luật mà agent dùng nó để quyết định hành động. Nó có thể là cứng (deterministic) và được kí hiệu là \(\mu\),
\[a_t = \mu(s_t)\]
hoặc được lấy mẫu từ một distribution (stochastic) và được kí hiệu bằng \(\pi\):
\[a_t \sim \pi(\cdot|s_t)\]
Bởi vì policy như là não của agent nên cũng sẽ có nhiều blogs và papers sử dụng agent và policy với ý nghĩa như nhau.
Với deep RL, các policy được parameterised nên chúng sẽ có notation như sau:
\[a_t = \mu_\theta(s_t)\]
# Deterministic, for demonstration only
mu_net = nn.Sequential(
nn.Linear(obs_dim, 64),
nn.Tanh(),
nn.Linear(64, 64),
nn.Tanh(),
nn.Linear(64, 3)
)
action = mu_net(state).argmax()
print(f"At state: {state}, Take action: {action}")
# Stochastic
pi_net = nn.Sequential(
nn.Linear(obs_dim, 64),
nn.Tanh(),
nn.Linear(64, 64),
nn.Tanh(),
nn.Linear(64, 3)
)
action_distribution = torch.softmax(pi_net(state), dim=0)
# Sample from the categorical distribution
sampled_action = torch.multinomial(action_distribution, num_samples=1)
print(f"At state: {state}, Take action: {sampled_action}")
3.4. Trajectories
Trajectory \(\tau\) là một chuỗi các states và actions của agent trong environment.
\[\tau = (s_0, a_0, s_1, a_1, ...)\]
\(s_0\)
là trạng thái ban đầu của agent trong environment, thường được kí hiệu bằng \(\rho_0\):
\[s_0 \sim \rho_0(\cdot).\]
Ở mỗi state bất kì, agent sẽ chọn một hành động và sau khi thực hiện hành động này thì môi trường sẽ chuyển sang một state mới và quá trình này được gọi là state transition. State transition được quyết định bởi môi trường, nó có thể được biểu diễn bằng hàm deterministic,
\[s_{t+1} = f(s_t, a_t)\]
hoặc stochastic,
\[s_{t+1} \sim P(\cdot|s_t, a_t)\]
- Note: Trajectories trong một vài tài liệu hoặc cách implementations, chúng còn được gọi là episodes hoặc rollouts.
3.5. Reward & Returns
Reward \(R\) là một trong những yếu tố quan trọng nhất khi bạn tự thiết kế môi trường cho agent. Nó phụ thuộc vào 3 yếu tố: trạng thái hiện tại, hành động của agent, và trạng thái tiếp theo,
\[r_t = R(s_t, a_t, s_{t+1})\]
Mục tiêu của agent là làm sao để đạt được tổng tích lũy phần thưởng lớn nhất trong một trajectory. Tổng tích lũy phần thưởng này trong RL được gọi là return và thông thường chúng có 2 cách biểu diễn. Một là finite-horizon undiscounted return,
\[R(\tau) = \sum_{t=0}^{T}r_t\]
hai là infinite-horizon discounted return
\[\qquad \qquad \qquad \qquad \begin{aligned}
R(\tau) = \sum_{t=0}^{\infty} \gamma^tr_t \quad \quad \text{Với } \gamma \in (0, 1)
\end{aligned}\]
3.6. Model-free và Model-based
Nếu bạn nhìn vào đầu mục và nghĩ tới 2 trường hợp dùng không dùng và dùng deep learning cho agent thì chưa đúng. Model-free và model-based dùng để ám chỉ liệu bài toán có hàm để biểu diễn environment hay chưa.
Với model-free, agent không có hoặc không học mô hình của môi trường. Agent trong case model-free này được thả vào môi trường và nhận về tín hiệu feedback từ môi trường. Ví dụ trong trường hợp đi thi, chúng ta không biết đề thi sẽ như thế nào và cách duy nhất để biết là thi 1 lần, 2 lần, 3 lần và dần dần sẽ rút ra kinh nghiệm.
Ngược lại, với model-based thì agent sẽ học hoặc đã có một mô hình mô tả được môi trường và biết được môi trường sẽ trả cho nó feedback gì khi nó thực hiện một hành động cụ thể. Với ví dụ trên, thì agent đã biết được đề thi sẽ hỏi những câu gì, dạng nào, …
| Phương pháp |
Điểm mạnh |
Điểm yếu |
| Model-Free RL |
- Đơn giản hơn để implement. |
- Cần rất, rất nhiều trials-and-errors. |
| |
- Không yêu cầu mô hình của môi trường. |
- Không thể lập kế hoạch dài hạn vì không biết trước các chuyển đổi trạng thái. |
| |
- Thường hiệu quả trong môi trường phức tạp và khó mô hình hóa. |
|
| Model-Based RL |
- Hiệu quả về mẫu, có thể lập kế hoạch bằng cách mô phỏng các bước trong tương lai. |
- Cần một mô hình chính xác của môi trường, điều này khó học và tốn kém. |
| |
- Tốt hơn trong việc planning. |
- Phức tạp hơn để triển khai do yêu cầu mô hình hóa môi trường. |
| |
- Có thể “tưởng tượng” các kết quả tương lai mà không cần tương tác trực tiếp |
- Nếu mô hình không chính xác, có thể dẫn đến các quyết định sai lầm (Sai 1 ly, đi rất nhiều công sức và tài nguyên). |
Với Model-based RL, chúng thường được sử dụng trong các mô phỏng hoặc games. Trong các vấn đề thực tế như áp dụng vào chứng khoán, xe tự hành thì phương pháp model-free chủ yếu được sử dụng. Và vì model-free là cách mà được sử dụng phổ biến nhất nên trong đa số các papers thì hướng nghiên cứu này có số lượng publications cao hơn rất nhiều so với model-based.
4. Kết luận
Trong bài viết trên, mình đã giới thiệu về reinforcement learning, ứng dụng, và những thuật ngữ quan trọng trong lĩnh vực này. Ở các phần tiếp theo, mình sẽ giới thiệu và implement về các giải thuật liên quan. Hy vọng các bạn cảm thấy hữu ích.
References
1. Part 1: Key Concepts in RL - OpenAI Spinning Up
2. A (Long) Peek into Reinforcement Learning
3. Reinforcement Learning An Introduction by Richard S. Sutton & Andrew G. Barto