Xin chào các bạn,
Trong bài post này, mình sẽ giới thiệu về nén data (data compression).
1. Giới thiệu
Nếu các bạn dùng máy tính, chắc chắn đã từng thấy từ “Compress file” khi right click vào một folder nào đó. Compress file này tức là mã hóa (encode) folder này lại thành một đoạn code có thể được giải mã với ít bits hơn nhằm giảm dung lượng lưu trữ của chúng để có thể dễ dàng di chuyển.
Vì vậy, nén data là lĩnh vực dùng các giải thuật để có thể mã hóa dữ liệu thành một đoạn dữ liệu có dung lượng nhỏ hơn và có thể giải mã để lấy lại dữ liệu gốc khi ta muốn. Data compression được chia thành 2 nhóm chính: lossy compression và lossless compression. Lossy compression là giải thuật nén ảnh làm mất một phần nào đó của dữ liệu gốc và lossless là giải thuật nén ảnh mà không làm mất dữ liệu gốc.
- Những khác biệt chính giữa lossy và lossless compression
| |
Lossy |
Lossless |
| Chất lượng |
Mất mát 1 phần |
Không mất |
| Applications |
Ảnh, videos, nhạc |
Ảnh, videos, nhạc, text |
| File types |
Images: JPEG |
Images: RAW, BMP, PNG |
| |
Video: MPEG, AVC, HEVC |
General: ZIP |
| |
Audio: MP3, AAC |
Audio: WAV, FLAC |
 Hình 1.1. Lossy vs Lossless compression
Hình 1.1. Lossy vs Lossless compression
2. Lossless Compression algorithms
Ở phần này, mình sẽ giới thiệu 2 giải thuật phổ biến để nén data mà không làm mất mát dữ liệu là Run Length Encoding, Huffman Encoding.
2.1. Run Length Encoding
Phương pháp này khá đơn giản cả về mặt lý thuyết và thực hiện, tuy tính hiệu quả của nó không quá cao và thậm chí có thể “phản dame”.
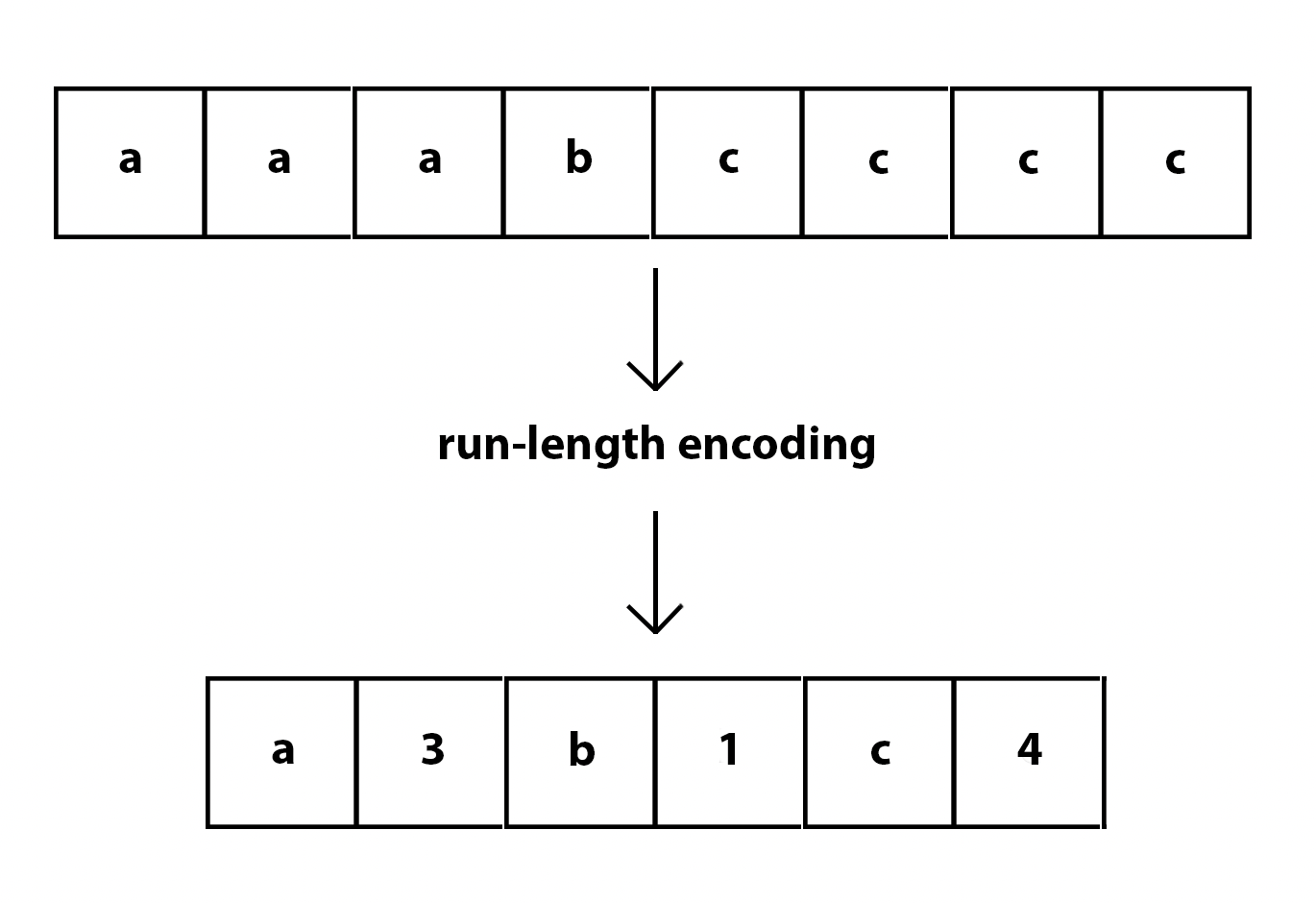 Hình 2.1.1. Cách hoạt động của Run Length Encoding
Hình 2.1.1. Cách hoạt động của Run Length Encoding
Như ở hình trên, các bạn cũng đã có thể mường tượng được cách làm việc của phương pháp này. Diễn giải bằng lời, run length encoding rút gọn dữ liệu bằng cách chèn số lần xuất hiện liên tiếp của 1 element vào vị trí đứng trước hoặc sau nó.
Ví dụ,
Ta có một chuỗi (string) A = “AAAABBBB” và số lượng bit cần lưu trữ là 8 bytes * 8 bits = 64 bits. Sau khi dùng RLE, ta có được kết quả “4A4B” và số lượng bit cần được lưu trữ là 4 bytes * 8 bits = 32 bits. Trong trường hợp này, việc sử dụng RLE đã giúp chúng ta giảm được 1 nửa số lượng dung lượng cần cấp cho file này.
Tuy nhiên trong trường hợp, data đứng tách rời nhau như “ABCDEFG” ta có được kết quả từ RLE “1A1B1C1D1E1F1G” thì số lượng luu trữ sẽ tăng gấp đôi. Vì vậy, việc sử dụng RLE có thể tăng số bits cần lưu trữ.
- Code
class RLE:
def __init__(self) -> None:
pass
@staticmethod
def encode(msg: str):
prev_char = msg[0]
frequency_list, element_list = [], []
cnt = 1
for i in range(1, len(msg)):
if msg[i] == prev_char:
cnt += 1
elif msg[i] != prev_char:
frequency_list.append(cnt)
element_list.append(prev_char)
prev_char = msg[i]
cnt = 1
frequency_list.append(cnt)
element_list.append(prev_char)
return frequency_list, element_list
@staticmethod
def decode(frequency_list: list,
element_list: list):
decoded_msg = ""
assert len(frequency_list) == len(element_list), \
"Length of frequency list != Length of element list. Please retry!"
for i in range(len(frequency_list)):
decoded_msg += frequency_list[i]*element_list[i]
return decoded_msg
string1 = "AAAA1122BBB"
string2 = "ABCDEFG"
encoded_string1 = RLE.encode(string1)
encoded_string2 = RLE.encode(string2)
decoded_string1 = RLE.decode(*encoded_string1)
decoded_string2 = RLE.decode(*encoded_string2)
print(f"Original string 1: {string1}, Encoded string 1: {encoded_string1}, Decoded string 1: {decoded_string1}")
print(f"Original string 2: {string2}, Encoded string 2: {encoded_string2}, Decoded string 2: {decoded_string2}")
Original string 1: AAAA1122BBB, Encoded string 1: ([4, 2, 2, 3], ['A', '1', '2', 'B']), Decoded string 1: AAAA1122BBB
Original string 2: ABCDEFG, Encoded string 2: ([1, 1, 1, 1, 1, 1, 1], ['A', 'B', 'C', 'D', 'E', 'F', 'G']), Decoded string 2: ABCDEFG
2.2. Huffman Encoding
Phương pháp Huffman Encoding dùng công thức thống kê (statistics) phức tạp hơn để encode data. Idea chính của giải thuật này là dùng số lượng bit ít để gán cho element có tần suất xuất hiện nhiều và ngược lại.
Ở phương pháp Run Length Encoding, giải thuật này “sợ” các trường hợp đứng tách rời nhau nhưng đối với Huffman, việc này đã được giải quyết. Vì vậy, dung lượng data được encode bởi Huffman sẽ luôn luôn nhỏ hơn hoặc bằng dung lượng ta cần cấp để lưu file gốc.
- Ví dụ minh họa tính tay của Huffman encoding
Giả sử chúng ta có một chuỗi 15 kí tự như sau cần được nén lại:
 Hình 2.2.1. Initial String
Hình 2.2.1. Initial String
Ban đầu, chuỗi này sẽ chiếm tổng cộng 15*8 = 120 bits cần được lưu trữ.
Bước 1: Tính toán tần suất của các ký tự
 Hình 2.2.1. Tần suất lần lượt của các ký tự B C A D
Hình 2.2.1. Tần suất lần lượt của các ký tự B C A D
Bước 2: Lọc chúng với giá trị từ thấp tới cao
 Hình 2.2.1. Giá trị tần suất từ thấp tới cao
Hình 2.2.1. Giá trị tần suất từ thấp tới cao
Bước 3: Tạo leaf node và gán giá trị của character vào node đó với thứ tự trái nhỏ hơn phải. Ngoài ra, tạo node parent bằng tổng 2 node của nhánh đó.
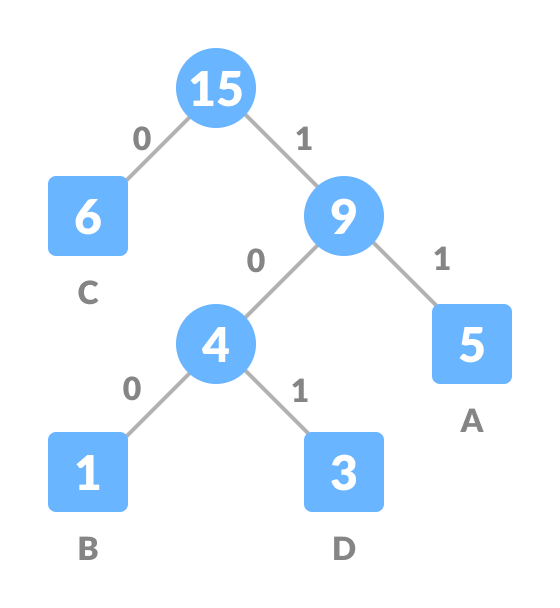 Hình 2.2.1. Giá trị tần suất từ thấp tới cao
Hình 2.2.1. Giá trị tần suất từ thấp tới cao
Với cách encoding như vậy, ta có bảng so sánh sau
| Character |
Frequency |
Code |
Size |
| A |
5 |
11 |
5*2 bits |
| B |
1 |
100 |
1 * 3 bits |
| C |
6 |
0 |
6 * 1 bits |
| D |
3 |
101 |
3 * 3 bits |
| |
15*8=120 bits |
|
28 bits |
Vì vậy ở trong bảng trên, cách mã hóa Huffman giúp ta tiết kiệm ~3 lần số bits cần lưu trữ.
string = 'BCAADDDCCACACAC'
# Creating tree nodes
class NodeTree(object):
def __init__(self, left=None, right=None):
self.left = left
self.right = right
def children(self):
return (self.left, self.right)
def nodes(self):
return (self.left, self.right)
def __str__(self):
return '%s_%s' % (self.left, self.right)
# Main function implementing huffman coding
def huffman_code_tree(node, left=True, binString=''):
if type(node) is str:
return {node: binString}
(l, r) = node.children()
d = dict()
d.update(huffman_code_tree(l, True, binString + '0'))
d.update(huffman_code_tree(r, False, binString + '1'))
return d
# Calculating frequency
freq = {}
for c in string:
if c in freq:
freq[c] += 1
else:
freq[c] = 1
freq = sorted(freq.items(), key=lambda x: x[1], reverse=True)
nodes = freq
while len(nodes) > 1:
(key1, c1) = nodes[-1]
(key2, c2) = nodes[-2]
nodes = nodes[:-2]
node = NodeTree(key1, key2)
nodes.append((node, c1 + c2))
nodes = sorted(nodes, key=lambda x: x[1], reverse=True)
huffmanCode = huffman_code_tree(nodes[0][0])
print(' Char | Huffman code ')
print('----------------------')
for (char, frequency) in freq:
print(' %-4r |%12s' % (char, huffmanCode[char]))
Char | Huffman code
----------------------
'C' | 0
'A' | 11
'D' | 101
'B' | 100
3. Lời kết
Trong bài viết này, mình đã trình bày về hai phương pháp nén dữ liệu phổ biến là Run Length Encoding (RLE) và Huffman Encoding. Mỗi phương pháp đều có những ưu và nhược điểm riêng, thích hợp cho các loại dữ liệu khác nhau và tình huống sử dụng khác nhau. RLE đơn giản và hiệu quả đối với các chuỗi dữ liệu có nhiều phần tử lặp lại liên tiếp, trong khi Huffman Encoding mạnh mẽ hơn và có thể tối ưu hóa kích thước lưu trữ cho mọi loại dữ liệu thông qua việc phân bổ số lượng bit dựa trên tần suất xuất hiện.
Qua phần giới thiệu lý thuyết và các đoạn mã mẫu, hy vọng các bạn đã hiểu rõ hơn về cách hoạt động và ứng dụng của hai phương pháp nén này. Nén dữ liệu không chỉ giúp tiết kiệm dung lượng lưu trữ mà còn tối ưu hóa việc truyền tải thông tin, đặc biệt quan trọng trong thời đại mà dữ liệu và thông tin trở thành nguồn tài nguyên quý giá.
Nếu có thắc mắc hoặc cần giải đáp thêm về các thuật toán nén khác, các bạn hãy để lại comment hoặc liên hệ trực tiếp với mình. Cảm ơn các bạn đã theo dõi và hy vọng bài viết này sẽ giúp ích cho các bạn trong việc hiểu và áp dụng các phương pháp nén dữ liệu trong công việc và học tập.
References
1. Huffman Encoding - Programiz
2. Run-length encoding (lossless data compression) - Inside code
2. ChatGPT - OpenAI