1. Giới thiệu
GANs (Generative Adversarial Networks) được giới thiệu lần đầu vào năm 2014 trong bài báo “Generative Adversarial Nets” của Ian J. Goodfellow và các cộng sự. Đây là một phương pháp học không giám sát (unsupervised learning) được sử dụng để tạo ra dữ liệu mới mang tính chân thực và đa dạng.
 Hình 1.1. Tất cả gương mặt trên đều được tạo bởi GANs
Hình 1.1. Tất cả gương mặt trên đều được tạo bởi GANs
Mô hình GANs có kiến trúc cực kỳ thú vị, bao gồm hai mạng chính: Generator và Discriminator, hoạt động theo cơ chế đối kháng. Generator cố gắng tạo ra dữ liệu giả mạo giống như dữ liệu thật, trong khi Discriminator cố gắng phân biệt giữa dữ liệu thật và dữ liệu giả. Qua quá trình huấn luyện, cả hai mạng này đều cải thiện chất lượng của mình, dẫn đến việc tạo ra dữ liệu giả ngày càng chân thực hơn.
 Hình 1.1. Ý tưởng của GANs
Hình 1.1. Ý tưởng của GANs
Mô hình GANs hoạt động dựa trên cơ chế đối kháng giữa hai mạng neural: Generator (người tạo) và Discriminator (người kiểm tra). Hãy tưởng tượng bạn đang đào tạo một người làm tiền giả (Generator) và một người kiểm tra tiền giả (Discriminator). Người làm tiền giả cố gắng tạo ra những tờ tiền giả trông giống như thật nhất có thể. Trong khi đó, người kiểm tra tiền sẽ cố gắng phân biệt giữa tờ tiền thật và tờ tiền giả.
Ban đầu, người làm tiền giả chưa có kỹ năng, nên tờ tiền giả trông rất khác so với tờ tiền thật, và người kiểm tra tiền dễ dàng phát hiện. Tuy nhiên, qua mỗi lần bị phát hiện, người làm tiền giả học hỏi từ những sai lầm và cải thiện kỹ năng của mình, tạo ra những tờ tiền giả ngày càng giống thật hơn. Đồng thời, người kiểm tra tiền cũng học hỏi và nâng cao khả năng phát hiện tiền giả.
Quá trình này tiếp diễn cho đến khi người làm tiền giả trở nên rất giỏi trong việc tạo ra những tờ tiền giả mà ngay cả người kiểm tra tiền cũng khó phát hiện. Kết quả cuối cùng là một mô hình Generator có khả năng tạo ra dữ liệu giả rất chân thực, tương tự như dữ liệu thật.
2. Toán của GANs
Ý tưởng chính của GANs đã được đề cập ở phần trên, bây giờ chúng ta hãy cùng đi vào phần toán để nắm bắt được cách hoạt động chi tiết của kiến trúc thú vị này nhé.
\[\min_{G} \max_{D} V(D, G) = \mathop{\mathbb{E}}_{x \sim p_{data}(x)[log(D(x))]} + \mathop{\mathbb{E}}_{z \sim p_{z}(z)[log(1 - D(G(z)))]}\]
\[V: Value function\]
\[D: Discriminator\]
\[G: Generator\]
Theo như công thức tác giả đề cập, thì mô hình discriminator muốn maximise value function trong khi generator tìm cách minimise nó. Ở vế trái của phương trình là expectation của mô hình Discriminator trên real data, tức là nếu discrimator nhận diện đúng càng nhiều các real data thì giá trị này càng lớn.
\[\mathop{\mathbb{E}}_{x \sim p_{data}(x)[log(D(x))]}: \text{High -> Good Discriminator}\]
\[\mathop{\mathbb{E}}_{x \sim p_{data}(x)[log(1 - D(x))]}: \text{High -> Bad Discriminator}\]
\[\mathop{\mathbb{E}}_{z \sim p_{z}(z)[log(1 - D(G(z)))]}: \text{High -> Good Discriminator}\]
\[\mathop{\mathbb{E}}_{z \sim p_{z}(z)[log(D(G(z)))]}: \text{High -> Bad Discriminator}\]
3. Implementation
Ở phần này, chúng ta sẽ implement một kiến trúc GAN đơn giản trên tập MNIST digits để xem chất lượng hình ảnh được sinh ra như thế nào nhé.
- Step 1: Import các thư viện cần thiết
import torch
from torch import nn, optim
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader, Dataset
from torchvision.datasets import MNIST
import torchvision
import torch.nn.functional as F
from tqdm import tqdm
import torchvision.utils as vutils
%matplotlib inline
transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
BATCH_SIZE = 64
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_loader = DataLoader(MNIST("./data/", train=True, download=True, transform=transform), batch_size = BATCH_SIZE, shuffle=True)
- Step 3: Xây dựng mô hình Generator và Discriminator
Đầu tiên, ta sẽ xây dựng khối convolution gồm Conv + Batch Norm + ReLU
class Conv(nn.Module):
def __init__(self, in_channels: int, out_channels: int,
kernel_size: int = 3, stride: int = 1, padding: int =1):
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, bias=False)
self.bn = nn.BatchNorm2d(out_channels)
self.act = nn.ReLU()
self.block = nn.Sequential(self.conv, self.bn, self.act)
def forward(self, x):
return self.block(x)
Sau khi có khối Conv, ta dùng nó để xây dựng discriminator và generator
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = Conv(1, 16, 3, 1, 1)
self.conv2 = Conv(16, 32, 3, 1, 1)
self.conv3 = Conv(32, 64, 3, 1, 1)
self.pooling = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(7*7*64, 1)
def forward(self, x: torch.Tensor):
x = self.conv1(x)
x = self.pooling(x)
x = self.conv2(x)
x = self.pooling(x)
x = self.conv3(x)
x = x.flatten(1)
x = self.fc1(x)
x = nn.Sigmoid()(x)
return x
class Generator(nn.Module):
def __init__(self, z_dim: int = 20):
super().__init__()
self.fc1 = nn.Linear(z_dim, 7*7*256)
self.conv1 = Conv(256, 128, 3, 1, 1)
self.conv2 = Conv(128, 64, 3, 1, 1)
self.conv3 = nn.Conv2d(64, 1, 1, 1, bias=True)
self.upsample = nn.UpsamplingBilinear2d(scale_factor=2)
def forward(self, x: torch.Tensor):
x = self.fc1(x)
x = x.reshape(-1, 256, 7, 7)
x = self.upsample(x)
x = self.conv1(x)
x = self.upsample(x)
x = self.conv2(x)
x = self.conv3(x)
x = nn.Sigmoid()(x)
return x
- Step 4: Thiết lập optimizer, epochs, learning rate, …
Z_DIM = 100
disc = Discriminator().to(DEVICE)
generator = Generator(Z_DIM).to(DEVICE)
GEN_LR = 1e-3
DISC_LR = 1e-3
gen_optimizer = optim.Adam(generator.parameters(), lr=GEN_LR, amsgrad=True)
disc_optimizer = optim.Adam(disc.parameters(), lr = DISC_LR, amsgrad=True)
loss_fn = nn.BCELoss()
Thử sinh ra một vài tấm ảnh trước khi train để xem nó nhìn như thế nào nhé.
sample_batch = torch.randn((5, Z_DIM))
generated_data = generator(sample_batch)
fig, ax = plt.subplots(1, 5, figsize=(15, 15))
for i in range(5):
ax[i].imshow(generated_data.detach().cpu()[i][0])
ax[i].set_title(f"Sample {i}")
 Hình 3.1. Data được sinh ra trước khi train model
Hình 3.1. Data được sinh ra trước khi train model
def train_1_epoch(loader):
gen_loss_value = 0
disc_loss_value = 0
for real_data, _ in tqdm(train_loader):
z = torch.randn((BATCH_SIZE, Z_DIM)).to(DEVICE)
generated_data = generator(z)
real_data = real_data.to(DEVICE)
disc_real_data = disc(real_data)
disc_fake_data = disc(generated_data.detach())
# Real data: 0 Fake data: 1
disc_loss = loss_fn(disc_fake_data, torch.ones_like(disc_fake_data)) + loss_fn(disc_real_data, torch.zeros_like(disc_real_data))
disc_optimizer.zero_grad()
disc_loss.backward(retain_graph=True)
disc_optimizer.step()
disc_fake_data = disc(generated_data)
gen_loss = loss_fn(disc_fake_data, torch.zeros_like(disc_fake_data))
gen_optimizer.zero_grad()
gen_loss.backward()
gen_optimizer.step()
gen_loss_value += gen_loss.item()
disc_loss_value += disc_loss.item()
return disc_loss_value, gen_loss_value
@torch.no_grad()
def visualise():
generator.eval()
z = torch.randn((16, Z_DIM)).to(DEVICE)
generated_data = generator(z).cpu()
fig, ax = plt.subplots(figsize=(10, 10))
plt.axis("off")
ax.imshow(np.transpose(vutils.make_grid(generated_data, padding=2, normalize=True), (1, 2, 0)))
plt.show()
generator.train()
-
- Và cuối cùng là hàm train cho toàn bộ quá trình
def train(epochs: int):
for i in range(1, epochs+1):
disc_loss_value, gen_loss_value = train_1_epoch(train_loader)
print(f"Epoch: {i} Discriminator Loss: {disc_loss_value} Generator Loss: {gen_loss_value}")
visualise()
- Step 6: Train model và quan sát
Ta train model với khoảng 500 epochs
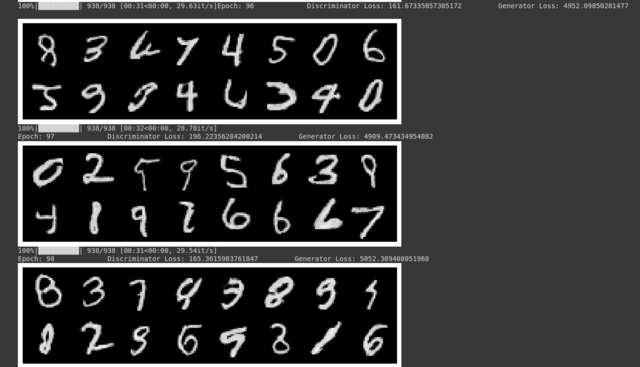 Hình 3.2. Data được sinh ra sau khi train model sau 90 epochs
Hình 3.2. Data được sinh ra sau khi train model sau 90 epochs
Lưu ý: Quá trình training GANs cực kì khó hội tụ và cần rất nhiều tài nguyên và thời gian để có thể tự train ra một mô hình sinh nhìn thật. Vì thế, mình khuyên các bạn dùng các pre-trained models của các công ty hay tổ chức lớn và fine-tune lại với dataset riêng thay vì train from scratch.
4. Kết luận
Qua bài viết này, chúng ta đã hiểu rõ về cấu trúc và cơ chế hoạt động của GANs, cũng như cách triển khai một mô hình GAN đơn giản để tạo ra hình ảnh từ tập dữ liệu MNIST. GANs là một công cụ mạnh mẽ trong việc tạo ra dữ liệu giả có chất lượng cao, được ứng dụng rộng rãi trong nhiều lĩnh vực như tạo ảnh, video, âm thanh và nhiều dạng dữ liệu khác. Việc nắm vững GANs sẽ mở ra nhiều cơ hội trong nghiên cứu và ứng dụng thực tế.
References
1. Generative Adversarial Nets - arXiv
2. DCGAN implementation from scratch