Xin chào các bạn!
Trong bài post này, mình sẽ giới thiệu về kiến trúc transformers. Đây được xem là một trong những model có tính cách mạng nhất trong deep learning vì nó đã tạo tiền đề cho sự ra đời của các mô hình ngôn ngữ lớn hay các mô hình SOTA cho các task như speech recognition, computer vision, …
Mô hình này được ra mắt nhằm thay thế cho kiến trúc Recurrent neural networks (RNNs), vốn đã được ra mắt vào những năm 90. Sơ lược thì kiến trúc recurrent này được thiết kế ra nhằm xử lý các loại thông tin có thứ tự như text, speech. Tuy nhiên, kiến trúc này có nhược điểm là vấn đề về exploding/vanishing gradient khi training nên nó không thể xử lý một đoạn thông tin quá dài. Vì những lý do đó mà Large language models không tồn tại trước khi transformer được ra mắt.
Đến năm 2014, một nhóm nghiên cứu ở Google đã nghiên cứu những phương pháp để khắc phục vấn đề trên của RNNs và đề xuất kiến trúc transformers. Chỉ sau 10 năm ra mắt, những thành tựu đạt được từ kiến trúc transformers nhiều không xuể với sự ra mắt của các mô hình ngôn ngữ lớn như ChatGPT, Llama3, Segment Anything, …
Ý tưởng chính của Transformers là cách sử dụng thông minh và khéo léo các phép tính toán song song (như nhân ma trận, ánh xạ, …) để thay thế các tính toán kiểu one-by-one của RNNs nhằm giải quyết vấn đề exploding/vanishing gradient.
2.1. Positional embedding
Transformers xử lý text một cách song song thay vì tuần tự như kiểu RNN, tức là nó sẽ cho nguyên cả đoạn text vào input cho 1 lần xử lý thay vì chia ra thành các timestep. Và vì trong các tín hiệu tuần tự thì thứ tự là một thông tin rất quan trọng. Ví dụ như “xin chào bạn” và nếu ta cho nó một thứ tự khác thì sẽ được câu như “chào xin bạn”, “bạn xin chào”. Như vậy, thứ tự có tính chất rất quan trọng để giữ lại được ngữ nghĩa của input. Khi xử lý tuần tự như kiểu RNNs thì ta không cần thông tin thứ tự vì timestep vốn đã là thứ tự rồi. Tuy nhiên đối với mô hình xử lý cả câu, cả đoạn một lúc như transformers thì phải có một thông tin thứ tự được chèn thêm vào để giúp mô hình này có thể biết được vị trí chính xác của từng từ trong input. Ashish Vaswani (1st author của paper) đã dùng một phương pháp để thực hiện việc này có tên là positional embedding.
- Công thức toán học của Positional Embedding
\[PE_{(pos, 2i)} = sin(\frac{pos}{10000^{\frac{2i}{d_{model}}}})\]
\[PE_{(pos, 2i + 1)} = cos(\frac{pos}{10000^{\frac{2i}{d_{model}}}})\]
Với,
\[pos: \text{Vị trí của phần từ trong input. Ex: 1, 2, ..., sequence length}\]
\[i: \text{Dimension thứ i của phần từ trong input: Ex: 1, 2, ...,} d_{model}\]
\[d_{model}: \text{Số dimension của input. Ex: 128 or 256 or 512 or any number}\]
2.2. Self-Attention
Trong các dữ liệu tuần tự như kiểu văn bản thì ngữ nghĩa của một từ ngoài phụ thuộc vào chính nó mà còn phụ thuộc vào các element đứng trước và sau. Ví dụ trong 2 câu sau “book a room” và “book in the room” thì từ book có 2 nghĩa hoàn toàn khác nhau. Để có thể phân biệt được từ “book” trong câu có nghĩa là đặt hay là quyển sách, ta phải dựa vào các từ kế bên trái và phải để có thể biết được. Và vì cần một cơ chế để có thể giúp nhận ra nghĩa của từ hiện tại dựa vào các từ bên cạnh, tác giá đã đề xuất cơ chế self-attention.
Một cách ngắn gọn, cơ chế self-attention giúp xác định ngữ nghĩa của 1 từ trong câu rõ ràng hơn. Self-attention cho biết sự “liên quan” của từ hiện tại với các từ còn lại trong input. Ví dụ self-attention của một input là text sẽ có dạng như sau:
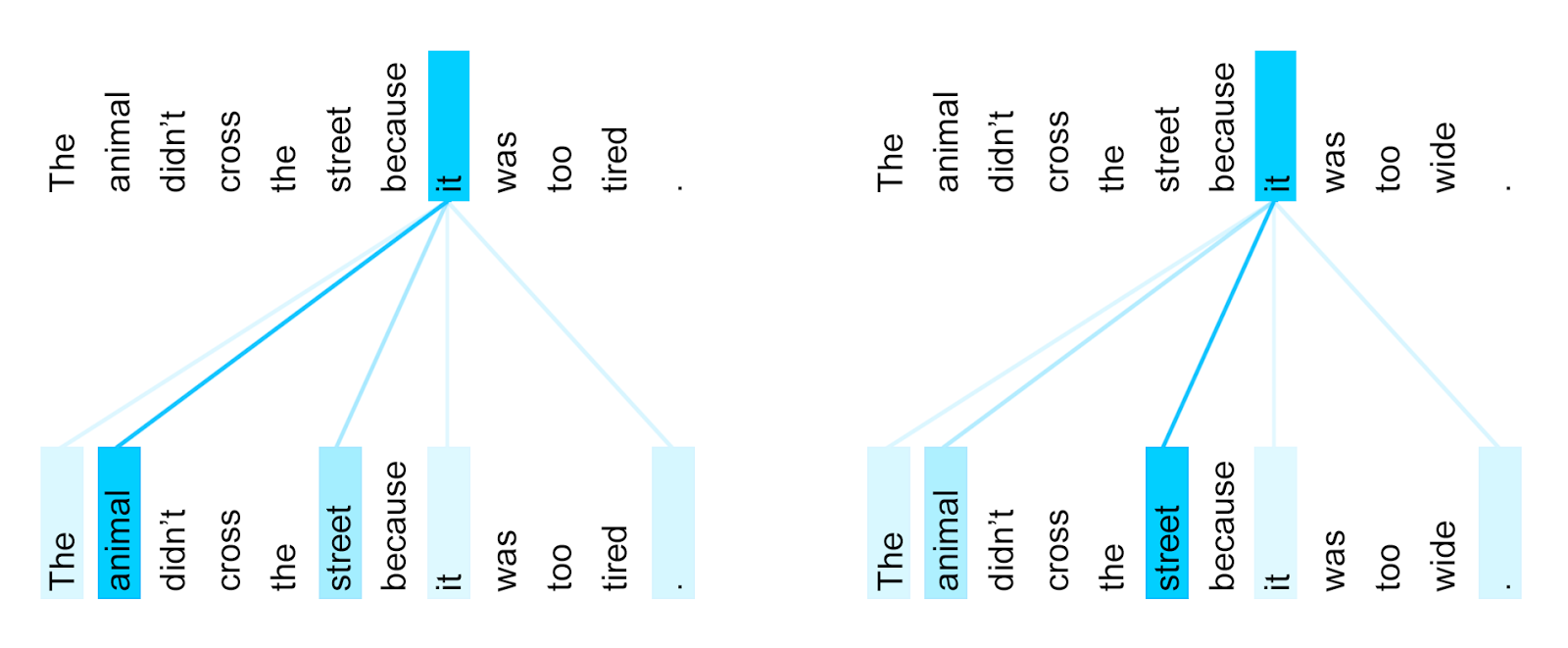 Hình 2.2.1. Ví dụ minh họa về self-attention - Google
Hình 2.2.1. Ví dụ minh họa về self-attention - Google
Ở câu trong hình trên, chỉ khác nhau ở 2 từ ở cuối câu là “tired” và “wide”. Nếu từ cuối cùng là “tired” thì từ “it” có attention score cao nhất (đường càng đậm thì có giá trị càng lớn) ở từ animal (ám chỉ rằng nó đang nói về animal) trong khi đó nếu từ cuối cùng là “wide” thì từ “it” sẽ có attention score cao nhất ở từ “street” nhằm ám chỉ rằng từ này đang có liên quan nhiều với từ “street” trong câu.
Nhờ có kiến trúc self-attention này, các ngữ nghĩa của 1 từ và các thông tin xung quanh được tích hợp lại một cách chặt chẽ đóng vai trò chính trong sự vượt trội của mô hình transformers so với các mô hình tiền nhiệm nó.
- Công thức toán học của Self-Attention
\[Attention(Q, K, V) = softmax(\frac{QK^{T}}{\sqrt d_k})V\]
Trong đó,
\[Q: Query, \R ^ {N \times d_k}\]
\[K: Key, \R ^ {N \times d_k}\]
\[V: Value, \R ^ {N \times d_v }\]
\[d_k: \text{Key dimension}\]
2.3. Multi Head Attention
Trong paper của mình, tác giả Ashish Vaswani cho rằng việc dùng thêm Linear layer để ánh xạ nó lên một không gian có h x d_embedding rồi thực hiện self-attention trên h x d_embedding đó sẽ “jointly attend to information from different representation
subspaces at different positions”. Mình không biết dịch đúng nghĩa đoạn trên như thế nào, nhưng ý tác giả muốn truyền tải rằng việc này sẽ giúp thông tin trong input kết nối với nhau ở nhiều chiều không gian hơn.
Với Multi Head Attention, tác giả dùng nhiều khối self-attention rồi ghép nối kết quả lại với nhau. Cụ thể, tác giả sẽ dùng h khối self-attention cho Q, K, V và sau đó concat kết quả cuối cùng.
 Hình 2.3.1. Khối self-attention (trái) và multi head attention (phải)
Hình 2.3.1. Khối self-attention (trái) và multi head attention (phải)
- Công thức toán học của Multi Head Attention
\[MultiHead(Q, K, V) = Concat(head_1, ..., head_h)W^O\]
Với,
\[head_i = Self Attention(QW_i^Q, KW_i^K, VW_i^V)\]
Trong đó,
\[W_i^Q \in \R^{d_{model} \times d_k}, W_i^K \in \R ^{d_{model} \times d_k}, W_i^V \in \R ^{d_{model} \times d_v}, W^O \in \R^{hd_v \times d_{model}}\]
Trong phần này, mình sẽ xây dựng kiến trúc transformer from scratch và train nó với 2 tasks để có thể giúp các bạn hiểu hơn về chi tiết về mô hình cũng như cách hoạt động của transformers trong NLP.
Kiến trúc tổng quan của transformers bao gồm 2 phần: Encoder và Decoder.
Nói thêm đoạn này: Autoregressive, encoder meaning and decoder meaning
 Hình 3.1.1. Kiến trúc tổng quan của mô hình Transformer - Paper
Hình 3.1.1. Kiến trúc tổng quan của mô hình Transformer - Paper
Với input embedding, ta cần xây dựng 2 khối chính là semantic embedding và positional embedding.
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class SemanticEmbedding(nn.Module):
def __init__(self, vocab_size: int = 1000,
embedding_dim: int = 256):
super().__init__()
self.embedder = nn.Parameter(torch.randn(vocab_size, embedding_dim))
def forward(self, input_sequence: torch.Tensor):
return self.embedder[input_sequence]
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int = 256, max_len: int = 1000):
super().__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype = torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float()*(-math.log(10000.0)*2./d_model))
pe[:, ::2] = torch.sin(position*div_term)
pe[:, 1::2] = torch.cos(position*div_term)
pe = pe.unsqueeze(0)
self.register_buffer("pe", pe)
def forward(self, x):
return self.pe[:, :x.size(1), :]
3.1.2. Multi-Head Attention
Ở phần này, chúng ta sẽ code khối Multi-Head Attention.
# Trước tiên là khối self-attention
class SelfAttention(nn.Module):
def forward(self, query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
mask: torch.Tensor = None,
dropout: nn.Dropout = None):
d_k = query.size(-1)
attention_score = F.softmax(torch.einsum("nqhd, nkhd -> nhqk", [query, key])/math.sqrt(d_k), -1)
if mask is not None:
attention_score = attention_score.masked_fill(mask==0, 1e-9)
if dropout is not None:
attention_score = dropout(attention_score)
output = torch.einsum("nhqk, nvhd -> nvhd", [attention_score, value])
return output
# Tiếp theo là khối Multi-Head Attention
class MultiHeadAttention(nn.Module):
def __init__(self, h, d_model, dropout_rate=0.1):
super().__init__()
assert d_model%h == 0
self.d_k = d_model//h
self.h = h
self.query_projector = nn.Linear(d_model, d_model)
self.key_projector = nn.Linear(d_model, d_model)
self.value_projector = nn.Linear(d_model, d_model)
self.output_linear = nn.Linear(d_model, d_model)
self.attention = SelfAttention()
self.dropout = nn.Dropout(dropout_rate)
def forward(self,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
mask: torch.Tensor=None):
batch_size = query.size(0)
projected_query = self.query_projector(query).view(batch_size, -1, self.h, self.d_k)
projected_key = self.key_projector(key).view(batch_size, -1, self.h, self.d_k)
projected_value = self.value_projector(value).view(batch_size, -1, self.h, self.d_k)
mha_output = self.attention(projected_query, projected_key, projected_value, mask, self.dropout).view(batch_size, -1, self.h*self.d_k)
output = self.output_linear(mha_output)
return mha_output
Sau khi code xong khối self-attention và self-attention, chúng ta sẽ test thử xem liệu output của các khối này có giống như chúng ta mong muốn không.
query = torch.randn((1, 10, 256))
key = torch.randn((1, 10, 256))
value = torch.randn((1, 15, 256))
multi_head_attention = MultiHeadAttention(4, 256)
print(multi_head_attention(query, key, value).shape)
Qua hình dạng của output, với output có dimension giống với kích thước của value tức là về shape nó đã đúng. Vì vậy, chúng ta sẽ qua bước tiếp theo là xây dựng bộ encoder và decoder.
3.1.3. Encoder
Khối encoder được xây dựng theo kiến trúc như bên trái hình 3.1.1. Khối này sẽ bao gồm 5 layers: Input Embedding, Multi-Head Attention, Add&Norm Layers, Feed Forward, Add&Norm Layer.
class TransformerEncoder(nn.Module):
def __init__(self, embedding_dim: int = 256,
num_heads: int = 4,
vocab_size: int = 10000,
max_seq_length: int = 100,
FF_dim: int = 1024):
super().__init__()
self.semantic_encoder = SemanticEmbedding(vocab_size, embedding_dim)
self.positional_encoder = PositionalEmbedding(d_model = embedding_dim, max_len=max_seq_length)
self.layer_norm_1 = nn.LayerNorm(embedding_dim)
self.feed_forward = nn.Sequential(nn.Linear(embedding_dim, FF_dim),
nn.ReLU(),
nn.Linear(FF_dim, embedding_dim))
self.layer_norm_2 = nn.LayerNorm(embedding_dim)
self.multi_head_attention = MultiHeadAttention(h = num_heads, d_model = embedding_dim)
def forward(self, x: torch.Tensor):
x = self.semantic_encoder(x)
x = x + self.positional_encoder(x)
x = self.layer_norm_1( x + self.multi_head_attention(x, x, x))
x = self.layer_norm_2(x + self.feed_forward(x))
return x
Sau khi build xong khối encoder, chúng ta sẽ thử xem output shape có giống như chúng ta mong đợi không nhé.
if __name__ == "__main__":
EMBEDDING_DIM = 256
NUM_HEADS = 4
VOCAB_SIZE = 10000
MAX_SEQ_LENGTH = 100
FF_DIM = 1024
encoder = TransformerEncoder(
embedding_dim=EMBEDDING_DIM,
num_heads=NUM_HEADS,
vocab_size=VOCAB_SIZE,
max_seq_length=MAX_SEQ_LENGTH,
FF_dim=FF_DIM,
)
sample = torch.arange(0, MAX_SEQ_LENGTH)
sample = (torch.rand((10, MAX_SEQ_LENGTH)) * (MAX_SEQ_LENGTH - 1)).long()
encoded_information = encoder(sample)
print(f"Sample: {sample}")
print(f"Encoded information: {encoded_information}")
print(f"Encoded information shape: {encoded_information.shape}")
3.1.4. Decoder
Cho classification task, chúng ta chỉ cần mỗi khối encoder của transformer vì đây là task không cần sinh ra output mới. Với classification task, chúng ta chỉ cần lấy feature được trích ra từ transformer encoder và đưa qua một lớp fully connected nữa để làm output cho classification.
Ở ví dụ này, mình sẽ dùng data từ tập Disaster Tweets từ Kaggle.
class CreateTextClassificationDataset(Dataset):
def __init__(
self,
df: pd.DataFrame,
vocabulary_size: int = None,
oov_token: str = "<OOV>",
padding_type: str = "post",
truncating_type: str = "post",
max_len: int = None,
):
self.sentences = df["text"].values.tolist()
self.labels = df["target"].values
self.vocabulary_size = vocabulary_size
self.oov_token = oov_token
self.padding_type = padding_type
self.truncating_type = truncating_type
self.max_len = max_len
# Create vectorised tokens
self._init_tokenizer()
self.vectorised_tokens = self._create_vectorised_tokens(self.sentences)
def _init_tokenizer(self) -> None:
self.tokenizer = Tokenizer(
num_words=self.vocabulary_size, oov_token=self.oov_token
)
self.tokenizer.fit_on_texts(self.sentences)
def _tokenize_texts(self, text: Union[str, List[str]]) -> List[int]:
tokens = self.tokenizer.texts_to_sequences(text)
return tokens
def _vectorise_tokens(self, tokens: Union[List, List[int]]):
if self.max_len is None:
self.max_len = max([len(token) for token in tokens])
padded = pad_sequences(
tokens,
padding=self.padding_type,
truncating=self.truncating_type,
maxlen=self.max_len,
)
return padded
def _create_vectorised_tokens(self, sentences: List[str]) -> np.array:
tokenised = self._tokenize_texts(sentences)
vectorised = self._vectorise_tokens(tokenised)
return vectorised
def __len__(self):
return len(self.sentences)
def __getitem__(self, idx):
return self.vectorised_tokens[idx], self.labels[idx]
class CreateEvalDatasetForEvaluation(Dataset):
def __init__(self, eval_tokens: np.array, eval_targets: np.array):
self.eval_tokens = eval_tokens
self.eval_targets = eval_targets
def __len__(self):
return self.eval_targets.shape[0]
def __getitem__(self, idx):
return self.eval_tokens[idx], self.eval_targets[idx]
- Step 2: Kết hợp transformer encoder và classification head
encoder = TransformerEncoder(
embedding_dim=EMBEDDING_DIM,
num_heads=NUM_HEADS,
vocab_size=VOCAB_SIZE,
max_seq_length=MAX_LEN,
FF_dim=FF_DIM,
)
model = nn.Sequential(encoder,
nn.Flatten(1),
nn.Linear(MAX_LEN*EMBEDDING_DIM, NUM_CLASSES))
model = model.to(DEVICE)
optimizer = optim.Adam(model.parameters(), lr = LR, amsgrad=True)
loss_fn = nn.CrossEntropyLoss()
- Step 3: Pre-training (Configs and stuff)
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
VOCAB_SIZE = 20000
OOV_TOKEN = "<OOV>"
PADDING_TYPE = "post"
TRUNCATING_TYPE = "post"
MAX_LEN = 33
NUM_TRAINING_RATIO = 0.8
EMBEDDING_DIM = 256
NUM_HEADS = 4
FF_DIM = 1024
BATCH_SIZE = 32
SHUFFLE = True
PIN_MEMORY = True
NUM_CLASSES = 2
LR = 3e-4
NUM_EPOCHS = 100
df = pd.read_csv("./nlp-getting-started/train.csv")
train_df = df.iloc[:int(NUM_TRAINING_RATIO*len(df))]
val_df = df.iloc[int(NUM_TRAINING_RATIO*len(df)):]
train_ds = CreateTextClassificationDataset(train_df, vocabulary_size=VOCAB_SIZE, oov_token=OOV_TOKEN, padding_type=PADDING_TYPE, truncating_type=TRUNCATING_TYPE,
max_len=MAX_LEN)
eval_tokens = train_ds._create_vectorised_tokens(val_df["text"].values.tolist())
eval_targets = val_df["target"].values
eval_ds = CreateEvalDatasetForEvaluation(eval_tokens, eval_targets)
train_loader = DataLoader(train_ds, batch_size = BATCH_SIZE, shuffle = SHUFFLE, pin_memory = PIN_MEMORY)
eval_loader = DataLoader(eval_ds, batch_size = BATCH_SIZE, shuffle=False, pin_memory=PIN_MEMORY)
def train_1_epoch():
model.train()
loss_sum = 0
for x, y in tqdm(train_loader):
x = x.long().to(DEVICE)
y = y.long().to(DEVICE)
logits = model(x)
loss = loss_fn(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_sum += loss.item()
return loss_sum
@torch.inference_mode()
def evaluate_1_epoch():
model.eval()
loss_sum = 0
correct_samples = 0
total_samples = 0
for x, y in tqdm(eval_loader):
x = x.long().to(DEVICE)
y = y.long().to(DEVICE)
logits = model(x)
loss = loss_fn(logits, y)
loss_sum += loss.item()
correct_samples += len(logits.max(-1)[-1][logits.max(-1)[-1] == y])
total_samples += logits.shape[0]
return loss_sum, correct_samples / total_samples
def train(NUM_EPOCHS: int):
for epoch in range(1, NUM_EPOCHS + 1):
train_loss = train_1_epoch()
val_loss, val_acc = evaluate_1_epoch()
torch.save(model.state_dict(), "last.pt")
print(
f"Epoch: {epoch}, Train Loss: {train_loss}, Val Loss: {val_loss}, Val Acc: {val_acc}"
)
train(NUM_EPOCHS=NUM_EPOCHS)
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 191/191 [00:14<00:00, 13.57it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 48/48 [00:00<00:00, 86.56it/s]
Epoch: 1, Train Loss: 142.10867008566856, Val Loss: 44.142126590013504, Val Acc: 0.5344714379514117
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 191/191 [00:11<00:00, 16.63it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 48/48 [00:00<00:00, 86.23it/s]
Epoch: 2, Train Loss: 125.55668744444847, Val Loss: 29.014512717723846, Val Acc: 0.6868023637557452
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 191/191 [00:12<00:00, 14.98it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 48/48 [00:00<00:00, 65.35it/s]
Epoch: 3, Train Loss: 112.70439422130585, Val Loss: 30.35796758532524, Val Acc: 0.6625082074852265
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 191/191 [00:11<00:00, 16.17it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 48/48 [00:00<00:00, 83.36it/s]
Epoch: 4, Train Loss: 98.53315824270248, Val Loss: 28.567470982670784, Val Acc: 0.7150361129349967
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 191/191 [00:11<00:00, 16.05it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 48/48 [00:00<00:00, 67.37it/s]
Epoch: 5, Train Loss: 87.58201515674591, Val Loss: 27.053630746901035, Val Acc: 0.7071569271175312
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 191/191 [00:16<00:00, 11.38it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 48/48 [00:00<00:00, 52.34it/s]
Epoch: 6, Train Loss: 79.27146698534489, Val Loss: 29.58349298685789, Val Acc: 0.7038739330269206
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 191/191 [00:16<00:00, 11.73it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 48/48 [00:00<00:00, 52.66it/s]
Epoch: 7, Train Loss: 71.90403440594673, Val Loss: 30.562148183584213, Val Acc: 0.7097833223900197
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 191/191 [00:14<00:00, 13.26it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 48/48 [00:00<00:00, 87.81it/s]
Epoch: 8, Train Loss: 60.30563969910145, Val Loss: 32.01201945543289, Val Acc: 0.6841759684832567
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 191/191 [00:12<00:00, 14.70it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 48/48 [00:00<00:00, 86.71it/s]
Epoch: 9, Train Loss: 56.01010598987341, Val Loss: 26.42184019088745, Val Acc: 0.7504924491135916
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 191/191 [00:12<00:00, 15.25it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 48/48 [00:00<00:00, 52.39it/s]
Epoch: 10, Train Loss: 45.02339556068182, Val Loss: 30.82352478429675, Val Acc: 0.7032173342087984
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 191/191 [00:16<00:00, 11.55it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 48/48 [00:00<00:00, 49.44it/s]
Epoch: 11, Train Loss: 37.822556521743536, Val Loss: 40.1178354145959, Val Acc: 0.7032173342087984
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 191/191 [00:16<00:00, 11.56it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 48/48 [00:00<00:00, 52.37it/s]
Epoch: 12, Train Loss: 28.31721487827599, Val Loss: 52.655704917619005, Val Acc: 0.6001313197636244
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 191/191 [00:14<00:00, 13.00it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 48/48 [00:00<00:00, 84.85it/s]
Epoch: 13, Train Loss: 28.7558862734586, Val Loss: 36.70165067911148, Val Acc: 0.7557452396585687
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 191/191 [00:13<00:00, 14.66it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 48/48 [00:00<00:00, 52.40it/s]
Epoch: 14, Train Loss: 20.431814706884325, Val Loss: 30.56316629052162, Val Acc: 0.7544320420223244
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 191/191 [00:15<00:00, 12.38it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 48/48 [00:00<00:00, 52.52it/s]
Epoch: 15, Train Loss: 16.69958796026185, Val Loss: 36.892881229519844, Val Acc: 0.7458962573867367
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 191/191 [00:16<00:00, 11.93it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 48/48 [00:00<00:00, 86.53it/s]
Epoch: 16, Train Loss: 16.344361373223364, Val Loss: 36.886749021708965, Val Acc: 0.7314510833880499
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 191/191 [00:11<00:00, 16.28it/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 48/48 [00:00<00:00, 85.07it/s]
Epoch: 17, Train Loss: 14.930934912525117, Val Loss: 32.301914274692535, Val Acc: 0.7386736703873933
Nhìn chung thì sau khoảng 17 epochs, model đạt 80% accuracy và có dấu hiệu bị overfit nhưng performance vẫn khá ổn.
Bước tiếp theo, mình sẽ thực hiện pipeline inference để chạy trực tiếp trên từng sample.
sample = ["Heard about #earthquake is different cities, stay safe everyone."]
vectorised_sample = train_ds._create_vectorised_tokens(sample)
vectorised_sample_torch = torch.from_numpy(vectorised_sample).long()
pred = model(vectorised_sample_torch).argmax(-1)
pred = "True" if pred.item() == 1 else "False"
print(f"Prediction of {sample[0]} is {pred}")
Prediction of Heard about #earthquake is different cities, stay safe everyone. is True
4. Lời kết
References
1. Attention is all you need - arXiv
| 2. [Positional embeddings in transformers EXPLAINED |
Demystifying positional encodings - Youtube]positional embedding |
3. Self Attention in Transformer Neural Networks (with Code!) - Youtube